SDK
Chat2Graph SDK 提供了一套简洁的 API,用于构建和扩展智能体系统。其设计旨在分离组件职责,支持模块化和可扩展性,帮助开发者高效构建自己的智能体系统。
1. SDK 的分层设计
如图所示, Chat2Graph SDK 是分层的,下层的模块支持上层的模块。最顶层是智能体(Agent),它代表了系统的核心执行单元和与用户交互的接口。智能体的具体行为和目标由其配置(Profile) 所定义,其任务的执行流程则通过工作流(Workflow) 进行编排。
工作流的执行依赖于下一层的引擎。算子(Operator) 作为任务执行的调度者,负责管理和驱动工作流中定义的步骤。为处理任务序列和依赖关系,算子利用 DAG 任务图(JobGraph) 来组织和追踪子任务。在执行过程中,评估器(Evaluator) 对算子中间结果或状态进行评估,以确保任务按预期方向推进。
这些上层组件的运作,依赖于基础能力层的支持:
- 推理器(
Reasoner) 是智能体认知能力的一部分,它封装了与大语言模型(LLM)的交互逻辑,使智能体能够进行理解、思考、规划和生成内容。 - 知识库(
KnowledgeBase) 为智能体提供持久化记忆和知识管理功能。它整合了记忆(Memory)、结构化知识(Knowledge),并能感知和利用系统环境(Environment) 信息。 - 工具包(
Toolkit) 则为智能体提供与外部世界交互和执行具体操作的机制。它通过定义一系列工具(Tool) 和动作(Action),使得智能体能够调用外部 API、访问环境(Environment)或执行特定的计算(Compute)任务。
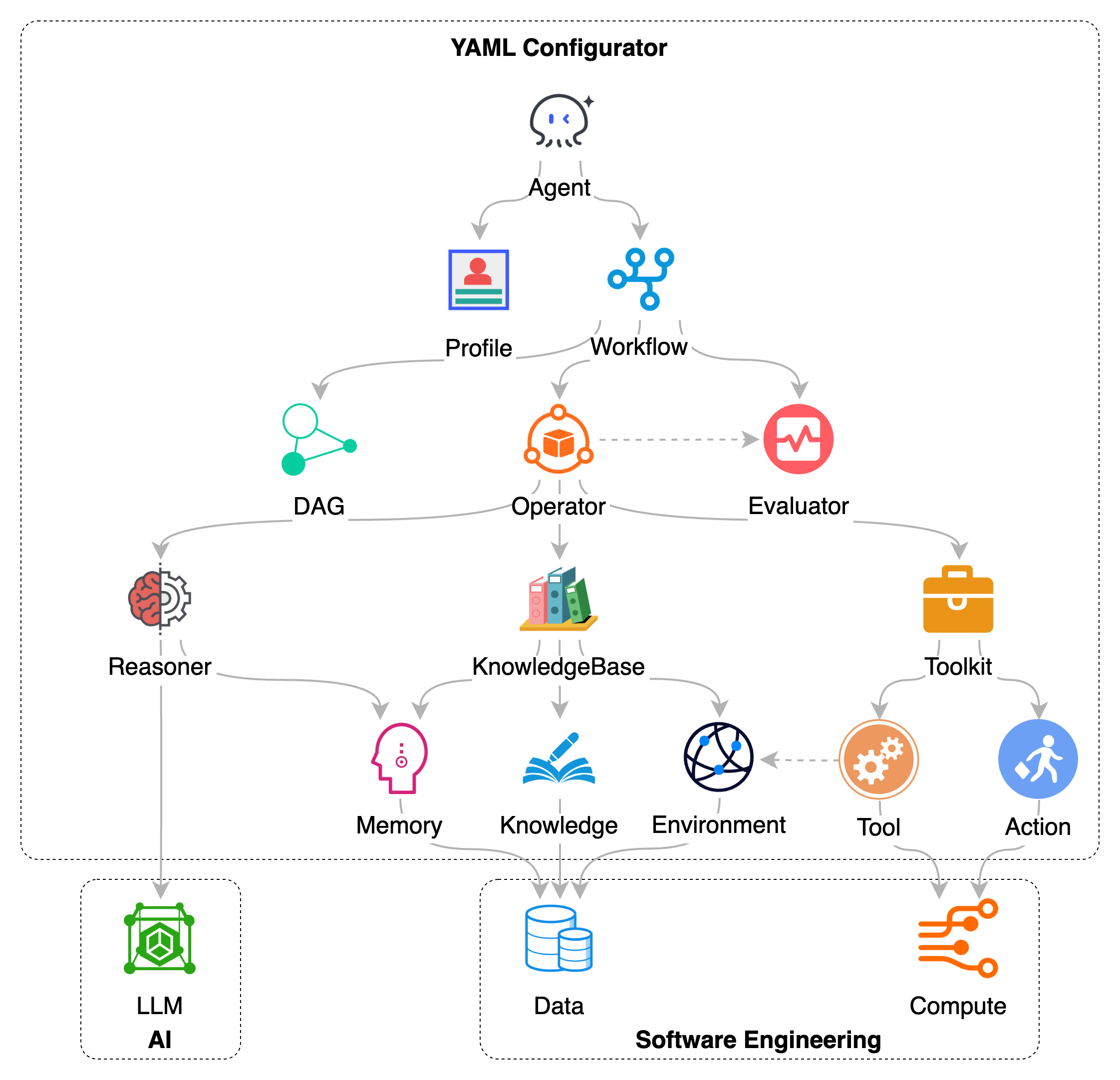
通过这种层层支持的架构,Chat2Graph SDK 允许开发者组合和配置这些组件。高层组件定义任务目标和流程,而底层组件提供执行所需的能力。这种设计思路旨在将大语言模型的认知能力与软件工程中的数据处理、计算资源利用和流程控制等实践相结合,构建一个更加全面的智能体应用。
2. SDK API
2.1. Reasoner
2.2. Toolkit
2.3. Agentic Service
Agentic Service 是 Chat2Graph SDK 的核心服务层,提供了完整的多代理系统管理和执行能力。该服务负责协调各个组件的初始化、配置和运行时交互。它在内部集成了多个服务组件,包括消息服务(MessageService)、会话服务(SessionService)、智能体服务(AgentService)、任务管理服务(JobService)、工具包服务(ToolkitService)和推理机服务(ReasonerService)。每个服务专注于特定的业务逻辑,同时通过统一的 Agentic Service 接口对外提供服务。
服务的执行流程采用任务驱动模式。当接收到用户消息时,系统会创建对应的 Job 对象,通过 JobWrapper 进行封装和提交。任务执行完成后,调用相关接口查询任务结果。
| 方法签名 | 描述 | 返回类型 |
|---|---|---|
session(session_id: Optional[str] = None) -> SessionWrapper | 获取或创建会话实例 | SessionWrapper |
reasoner(reasoner_type: ReasonerType = ReasonerType.DUAL) -> AgenticService | 配置推理器类型,支持链式调用 | AgenticService |
toolkit(*action_chain: Union[Action, Tuple[Action, ...]]) -> AgenticService | 配置工具包动作链,支持链式调用 | AgenticService |
leader(name: str, description: Optional[str] = None) -> AgentWrapper | 创建和配置 Leader 代理包装器 | AgentWrapper |
expert(name: str, description: Optional[str] = None) -> AgentWrapper | 创建和配置 Expert 代理包装器 | AgentWrapper |
graph_db(graph_db_config: GraphDbConfig) -> AgenticService | 配置图数据库连接 | AgenticService |
load(yaml_path: Union[str, Path], encoding: str = "utf-8") -> AgenticService | 从 YAML 配置文件加载服务配置 | AgenticService |
execute(message: Union[TextMessage, str]) -> ChatMessage | 同步执行用户消息,调用多智能体系统处理消息,返回结果(需要等待一定时间,约几分钟) | ChatMessage |
3. YAML 文件配置
Chat2Graph 支持通过 YAML 配置文件进行声明式的系统配置。配置文件采用分层结构,包含基本应用信息、插件、推理机、工具包、算子、工作流和智能体等多个部分。
配置文件的核心优势在于将系统的复杂配置外部化,使得不同的业务场景可以通过修改配置文件快速适配,而无需修改核心代码。工具和动作的配置采用引用机制,避免重复定义,提高可维护性。代理的工作流配置支持算子链和评估器的灵活组合,满足不同专家的特定需求。
通过 AgenticService.load() 方法,系统能够解析 YAML 配置并自动完成系统初始化等复杂的配置过程,大大简化了系统的部署和配置工作。
以下,我们提供一个包含注释的 YAML 参考文档,供用户理解和个性化配置:
4. 系统环境配置
Chat2Graph 管理环境变量,通过 SystemEnv 类提供统一的配置访问接口。该设计允许系统从多个来源获取配置值,并按照优先级进行覆盖。
其环境变量配置主要包括,大语言模型和嵌入模型调用参数、数据库配置、知识库配置、大模型默认生成语言以及系统运行参数等。开发者可以通过修改 .env 文件或设置环境变量来快速调整系统参数(可以通过全局搜索对应环境变量,查找源码,来深入了解每个参数的功能)。
环境变量的赋值优先级顺序为:.env 文件配置 > 操作系统环境变量 > 系统默认值。当系统启动时,SystemEnv 会自动加载 .env 文件中的配置(只加载一次),并将其与操作系统环境变量和预定义的默认值进行合并。每个环境变量都具有明确的类型定义和默认值,系统会自动进行类型转换和验证(支持类型转换的类型有:bool、str、int、float 以及自定义枚举类型如 WorkflowPlatformType、ModelPlatformType 等)。
此外,环境变量配置管理采用延迟加载和缓存机制。环境变量值在首次访问时被解析和缓存,后续访问直接从缓存中获取。同时,系统支持运行时动态修改配置值,方便调试和测试。
4.1. 模型兼容性说明
Chat2Graph 支持所有兼容 OpenAI API 标准的大语言模型和嵌入模型,包括但不限于:
大语言模型支持:
- Google Gemini 系列(Gemini 2.0 Flash、Gemini 2.5 Flash、Gemini 2.5 Pro 等,必须选择兼容 OpenAI 接口的版本)
- OpenAI 系列(GPT-4o、o3-mini 等)
- Anthropic Claude 系列(Claude Opus 4、Claude Sonnet 4、Claude Sonnet 3.7、Claude Sonnet 3.5 等,必须选择兼容 OpenAI 接口的版本)
- 阿里通义千问系列(Qwen-3)
- 智谱 GLM 系列
- DeepSeek 系列
- 以及其他支持 OpenAI API 格式的模型服务,比如硅基流动等
嵌入模型支持:
- OpenAI Embedding 系列(text-embedding-3-small、text-embedding-3-large 等)
- Gemini Embedding 系列(选择兼容 OpenAI 接口的版本)
- 阿里通义千问嵌入模型(text-embedding-v3 等)
- 其他兼容 OpenAI Embeddings API 的模型
只需在 .env 文件中配置相应的模型名称、API 端点和密钥即可使用。系统会自动处理不同模型服务商的 API 调用细节。根据测试经验,推荐使用 Gemini 2.0 Flash、Gemini 2.5 Flash 或 o3-mini 等模型以获得更好的推理效果和性价比。
5. 示例
- YAML 配置构建:
test/example/agentic_service/load_service_by_yaml.py- 系统默认 YAML 配置示例:
app/core/sdk/chat2graph.yml
- 系统默认 YAML 配置示例:
- SDK 编程式构建:
test/example/agentic_service/load_service_by_sdk.py - 无会话服务执行:
test/example/agentic_service/run_agentic_service_without_session.py - 会话服务执行:
test/example/agentic_service/run_agentic_service_with_session.py