SDK
The Chat2Graph SDK provides a concise set of APIs for building and extending agent systems. Its design focuses on separating component responsibilities while supporting modularity and extensibility, helping developers efficiently construct their own agent systems.
1. Layered Design of the SDK
As shown in the diagram, the Chat2Graph SDK is layered, with lower-level modules supporting upper-level ones. At the top is the Agent, representing the core execution unit and user interaction interface of the system. An agent's specific behaviors and objectives are defined by its Profile, while its task execution flow is orchestrated through Workflow.
Workflow execution relies on the next layer of engines. The Operator, as the task execution scheduler, manages and drives the steps defined in the workflow. To handle task sequences and dependencies, operators use DAG JobGraph to organize and track subtasks. During execution, the Evaluator assesses intermediate results or states to ensure tasks progress as expected.
The operation of these upper-level components depends on foundational capabilities:
- Reasoner is part of the agent's cognitive abilities, encapsulating interaction logic with large language models (LLMs) to enable understanding, reasoning, planning, and content generation.
- KnowledgeBase provides the agent with persistent memory and knowledge management functions. It integrates Memory, structured Knowledge, and can perceive and utilize Environment information.
- Toolkit equips the agent with mechanisms to interact with the external world and perform specific operations. By defining a series of Tools and Actions, it enables the agent to call external APIs, access the Environment, or execute specific computational tasks.
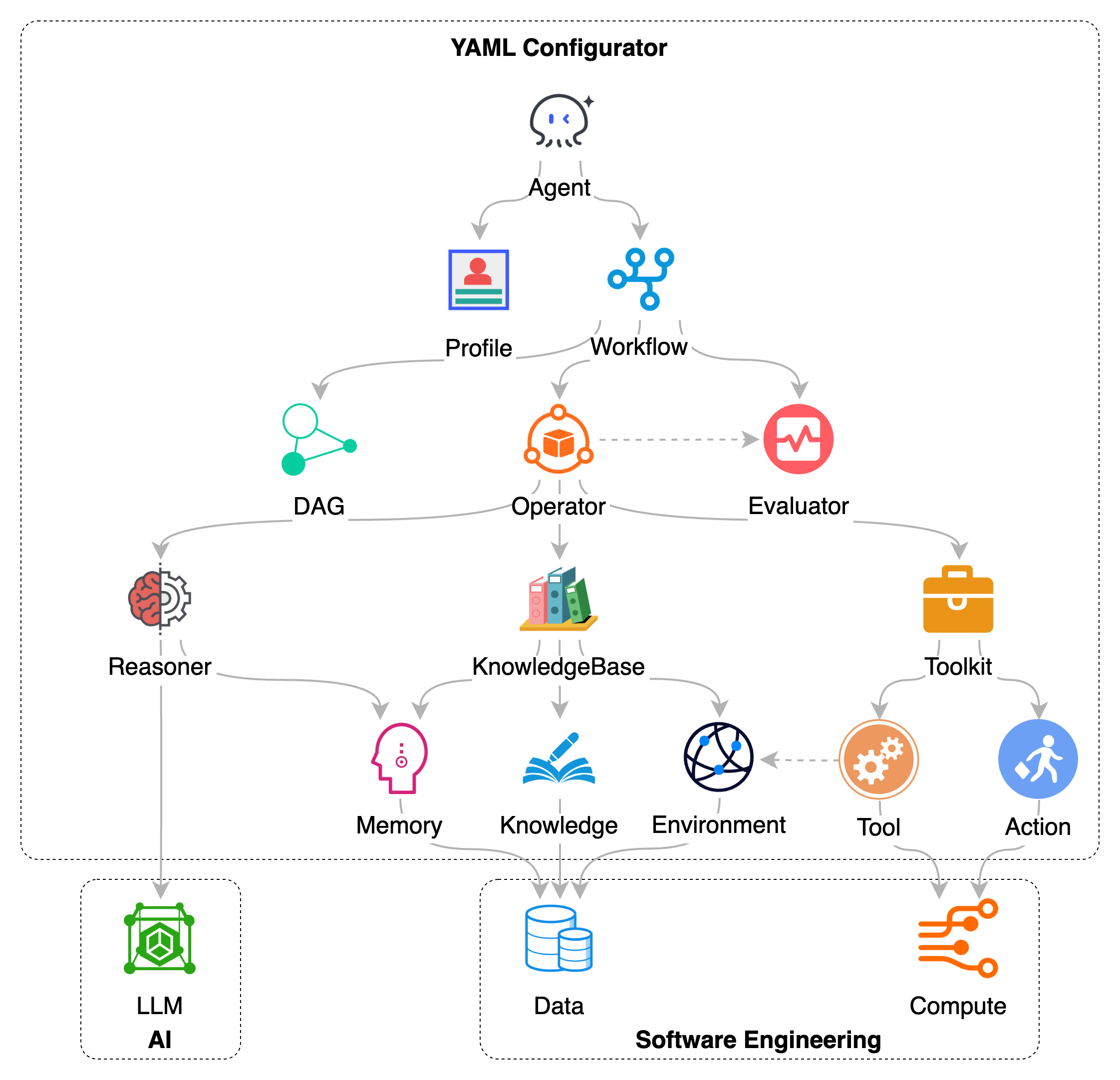
Through this layered architecture, the Chat2Graph SDK allows developers to combine and configure these components. High-level components define task objectives and flows, while lower-level components provide execution capabilities. This design aims to integrate the cognitive abilities of LLMs with software engineering practices like data processing, computational resource utilization, and workflow control to build more comprehensive agent applications.
2. SDK API
2.1. Reasoner
2.2. Toolkit
2.3. Agentic Service
Agentic Service is the core service layer of Chat2Graph SDK, providing comprehensive multi-agent system management and execution capabilities. It coordinates the initialization, configuration, and runtime interactions of various components. Internally, it integrates multiple service components including MessageService, SessionService, AgentService, JobService, ToolkitService, and ReasonerService. Each service focuses on specific business logic while offering unified Agentic Service interfaces externally.
The service execution follows a task-driven model. When receiving a user message, the system creates a corresponding Job object, encapsulates it with JobWrapper, and submits it. After task completion, relevant interfaces are called to query the results.
| Method Signature | Description | Return Type |
|---|---|---|
session(session_id: Optional[str] = None) -> SessionWrapper | Gets or creates a session instance | SessionWrapper |
reasoner(reasoner_type: ReasonerType = ReasonerType.DUAL) -> AgenticService | Configures the reasoner type, supporting method chaining | AgenticService |
toolkit(*action_chain: Union[Action, Tuple[Action, ...]]) -> AgenticService | Configures the toolkit action chain, supporting method chaining | AgenticService |
leader(name: str, description: Optional[str] = None) -> AgentWrapper | Creates and configures a Leader agent wrapper | AgentWrapper |
expert(name: str, description: Optional[str] = None) -> AgentWrapper | Creates and configures an Expert agent wrapper | AgentWrapper |
graph_db(graph_db_config: GraphDbConfig) -> AgenticService | Configures graph database connection | AgenticService |
load(yaml_path: Union[str, Path], encoding: str = "utf-8") -> AgenticService | Loads service configuration from a YAML file | AgenticService |
execute(message: Union[TextMessage, str]) -> ChatMessage | Synchronously executes a user message, invoking the multi-agent system to process the message and return results (may take several minutes) | ChatMessage |
3. YAML Configuration
Chat2Graph supports declarative system configuration via YAML files. The configuration file adopts a hierarchical structure, including basic application info, plugins, reasoners, toolkits, operators, workflows, and agents.
The core advantage of YAML configuration is externalizing complex system setups, allowing quick adaptation to different business scenarios without modifying core code. Tool and action configurations use reference mechanisms to avoid redundancy and improve maintainability. Agent workflows support flexible combinations of operator chains and evaluators to meet diverse expert requirements.
Through the AgenticService.load() method, the system parses YAML configurations and automatically completes complex setup processes like initialization, significantly simplifying deployment and configuration.
Below is an annotated YAML reference document for understanding and customization:
4. System Environment Configuration
Chat2Graph manages environment variables through the SystemEnv class, providing a unified configuration access interface. This design allows the system to retrieve configuration values from multiple sources with priority-based overrides.
The environment variable configuration primarily includes: large language model and embedding model invocation parameters, database configuration, knowledge base configuration, default generation language for large models, and system runtime parameters. Developers can quickly adjust system parameters by modifying the .env file or setting environment variables (you can search globally for corresponding environment variables and examine the source code to gain deeper insights into each parameter's functionality).
The priority order for environment variable assignment is: .env file configuration > OS environment variables > system default values. When the system starts, SystemEnv automatically loads configurations from the .env file (once only) and merges them with OS environment variables and predefined default values. Each environment variable has explicit type definitions and default values, with automatic type conversion and validation (supported types include: bool, str, int, float, and custom enum types such as WorkflowPlatformType, ModelPlatformType, etc.).
Additionally, the environment variable configuration management employs lazy loading and caching mechanisms. Environment variable values are parsed and cached upon first access, with subsequent accesses retrieving directly from the cache. The system also supports runtime dynamic modification of configuration values, facilitating debugging and testing.
4.1. Model Compatibility Notes
Chat2Graph supports all large language models and embedding models compatible with the OpenAI API standard, including but not limited to:
Supported Large Language Models:
- Google Gemini series (Gemini 2.0 Flash, Gemini 2.5 Flash, Gemini 2.5 Pro, etc. Must select versions Compatible with OpenAI Interface)
- OpenAI series (GPT-4o, o3-mini, etc.)
- Anthropic Claude series (Claude Opus 4, Claude Sonnet 4, Claude Sonnet 3.7, Claude Sonnet 3.5, etc. Must select versions Compatible with OpenAI Interface)
- Alibaba Tongyi Qianwen series (Qwen-3)
- Zhipu GLM series
- DeepSeek series
- Other model services supporting OpenAI API format
Supported Embedding Models:
- OpenAI Embedding series (text-embedding-3-small, text-embedding-3-large, etc.)
- Gemini Embedding series (select versions compatible with OpenAI interface)
- Alibaba Tongyi Qianwen embedding models (text-embedding-v3, etc.)
- Other models compatible with OpenAI Embeddings API, such as SiliconFlow, etc.
Simply configure the corresponding model name, API endpoint, and key in the .env file to use them. The system automatically handles API call details for different model providers. Based on testing experience, we recommend using models like Gemini 2.0 Flash, Gemini 2.5 Flash, or o3-mini for better inference performance and cost-effectiveness.
5. Examples
- YAML Configuration Construction:
test/example/agentic_service/load_service_by_yaml.py- Default System YAML Configuration Example:
app/core/sdk/chat2graph.yml
- Default System YAML Configuration Example:
- SDK Programmatic Construction:
test/example/agentic_service/load_service_by_sdk.py - Sessionless Service Execution:
test/example/agentic_service/run_agentic_service_without_session.py - Session-based Service Execution:
test/example/agentic_service/run_agentic_service_with_session.py